unordered_map、unordered_set 底层原理及其相关面试题
(1)unordered_map、unordered_set的底层原理
unordered_map的底层是一个防冗余的哈希表(采用除留余数法)。哈希表最大的优点,就是把数据的存储和查找消耗的时间大大降低,时间复杂度为O(1);而代价仅仅是消耗比较多的内存。
使用一个下标范围比较大的数组来存储元素。可以设计一个函数(哈希函数(一般使用除留取余法),也叫做散列函数),使得每个元素的key都与一个函数值(即数组下标,hash值)相对应,于是用这个数组单元来存储这个元素;也可以简单的理解为,按照key为每一个元素“分类”,然后将这个元素存储在相应“类”所对应的地方,称为桶。
但是,不能够保证每个元素的key与函数值是一一对应的,因此极有可能出现对于不同的元素,却计算出了相同的函数值,这样就产生了“冲突”,换句话说,就是把不同的元素分在了相同的“类”之中。 一般可采用拉链法解决冲突:
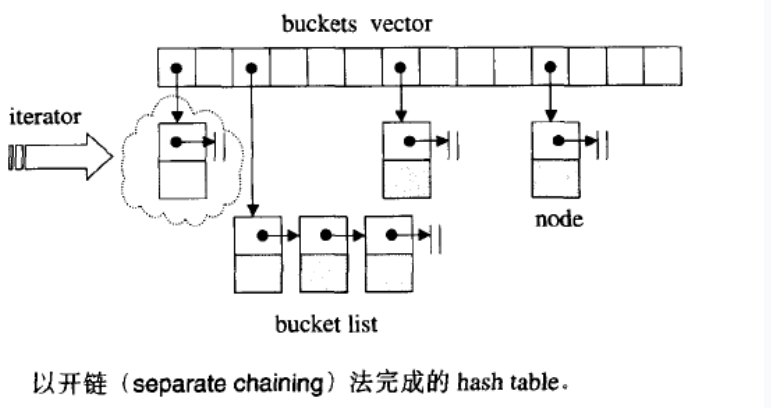
(2)哈希表的实现
#include <iostream>
#include <vector>
#include <list>
#include <random>
#include <ctime>
using namespace std;
const int hashsize = 12;
//定一个节点的结构体
template <typename T, typename U>
struct HashNode
{
T _key;
U _value;
};
//使用拉链法实现哈希表类
template <typename T, typename U>
class HashTable
{
public:
HashTable() : vec(hashsize) {}//类中的容器需要通过构造函数来指定大小
~HashTable() {}
bool insert_data(const T &key, const U &value);
int hash(const T &key);
bool hash_find(const T &key);
private:
vector<list<HashNode<T, U>>> vec;//将节点存储到容器中
};
//哈希函数(除留取余)
template <typename T, typename U>
int HashTable<T, U>::hash(const T &key)
{
return key % 13;
}
//哈希查找
template <typename T, typename U>
bool HashTable<T, U>::hash_find(const T &key)
{
int index = hash(key);//计算哈希值
for (auto it = vec[index].begin(); it != vec[index].end(); ++it)
{
if (key == it -> _key)//如果找到则打印其关联值
{
cout << it->_value << endl;//输出数据前应该确认是否包含相应类型
return true;
}
}
return false;
}
//插入数据
template <typename T, typename U>
bool HashTable<T, U>::insert_data(const T &key, const U &value)
{
//初始化数据
HashNode<T, U> node;
node._key = key;
node._value = value;
for (int i = 0; i < hashsize; ++i)
{
if (i == hash(key))//如果溢出则把相应的键值添加进链表
{
vec[i].push_back(node);
return true;
}
}
}
int main(int argc, char const *argv[])
{
HashTable<int, int> ht;
static default_random_engine e;
static uniform_int_distribution<unsigned> u(0, 100);
long long int a = 10000000;
for (long long int i = 0; i < a; ++i)
ht.insert_data(i, u(e));
clock_t start_time = clock();
ht.hash_find(114);
clock_t end_time = clock();
cout << "Running time is: " << static_cast<double>(end_time - start_time) / CLOCKS_PER_SEC * 1000 <<
"ms" << endl;//输出运行时间。
system("pause");
system("pause");
return 0;
}
(3)unordered_map 与map的区别?使用场景?
构造函数:unordered_map 需要hash函数,等于函数;map只需要比较函数(小于函数).
存储结构:unordered_map 采用hash表存储,map一般采用红黑树(RB Tree) 实现。因此其memory数据结构是不一样的。
总体来说,unordered_map 查找速度会比map快,而且查找速度基本和数据数据量大小,属于常数级别;而map的查找速度是log(n)级别。并不一定常数就比log(n)小,hash还有hash函数的耗时,明白了吧,如果你考虑效率,特别是在元素达到一定数量级时,考虑考虑unordered_map 。但若你对内存使用特别严格,希望程序尽可能少消耗内存,那么一定要小心,unordered_map 可能会让你陷入尴尬,特别是当你的unordered_map 对象特别多时,你就更无法控制了,而且unordered_map 的构造速度较慢。
(4)unordered_map、unordered_set的常用函数
unordered_map.begin() 返回指向容器起始位置的迭代器(iterator)
unordered_map.end() 返回指向容器末尾位置的迭代器
unordered_map.cbegin() 返回指向容器起始位置的常迭代器(const_iterator)
unordered_map.cend() 返回指向容器末尾位置的常迭代器
unordered_map.size() 返回有效元素个数
unordered_map.insert(key) 插入元素
unordered_map.find(key) 查找元素,返回迭代器
unordered_map.count(key) 返回匹配给定主键的元素的个数
评论(2)
不显图啊
已更改,不过好久没看评论了,,好像有点忘了,,