Hash设计原理之开放地址法(下)
Hash碰撞


比如说我的输入是任意一个自然数(0,1,2,3…),而我要求经过一个函数后我的输出的数的范围要在0-9这样一个范围之间。
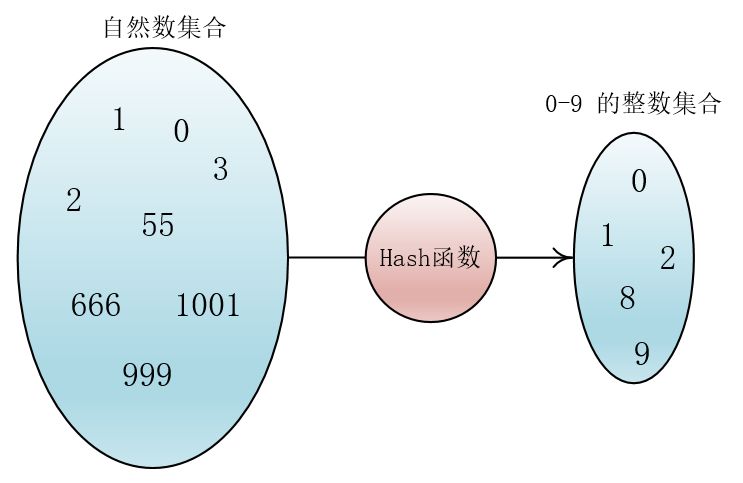
很容易想到,我们可以使用Hash函数:
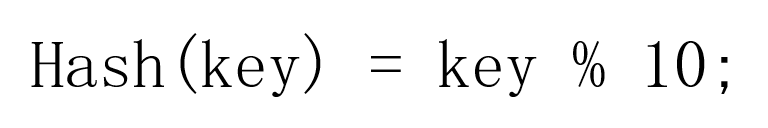
其中key就是输入
在哈希表(散列表)里,Hash函数的作用就是将关键字Key转化为一个固定长度数组的下标,以便存取键值对<Key,Value>
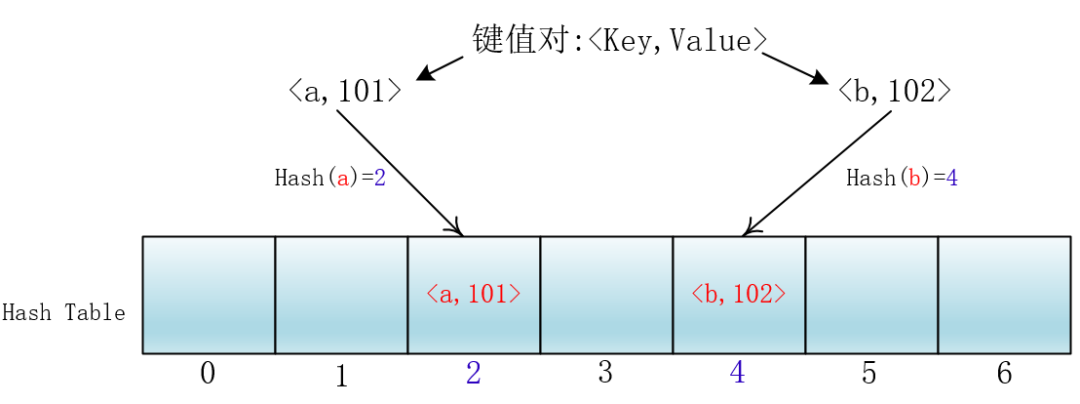


链地址法可看:神速Hash
开放地址法


所谓开放地址法就是发生冲突时在散列表(也就是数组里)里去寻找合适的位置存取对应的元素。
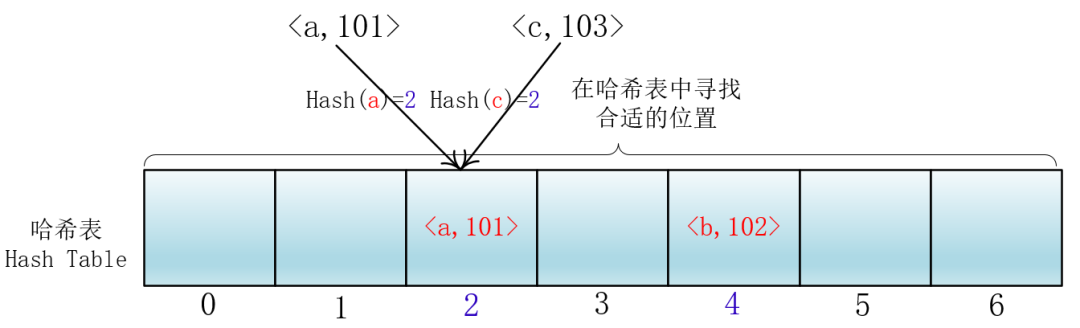


线性探测法
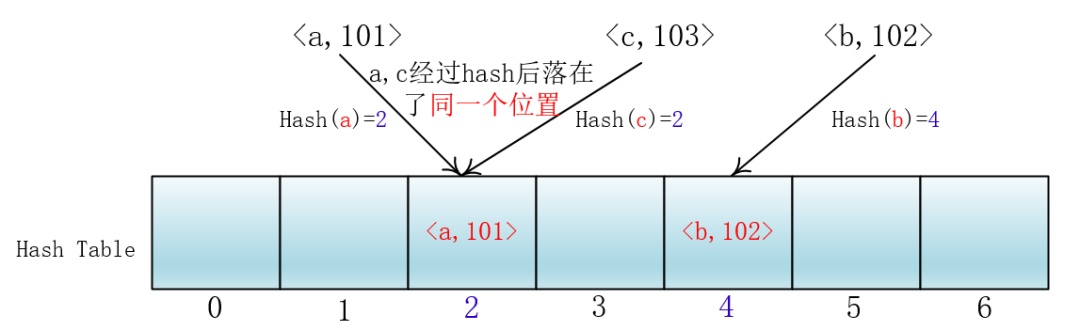
最容易想到的就是当前位置冲突了,那我就去找相邻的下一个位置。
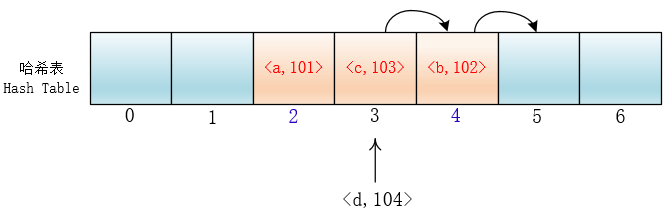
就拿放入元素举例吧,当你放入<a,101>到下标为2的位置后,另一个<c,103>键值对也落入了这个位置,那么它就向后依次加一寻找合适的位置,然后把<c,103>放入进去。
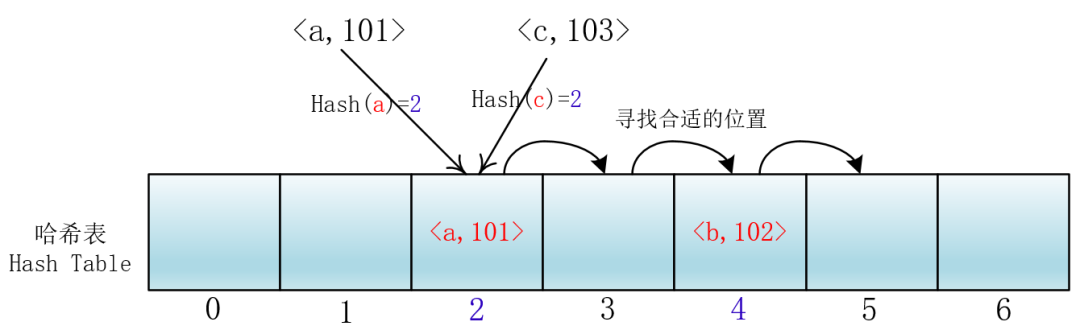
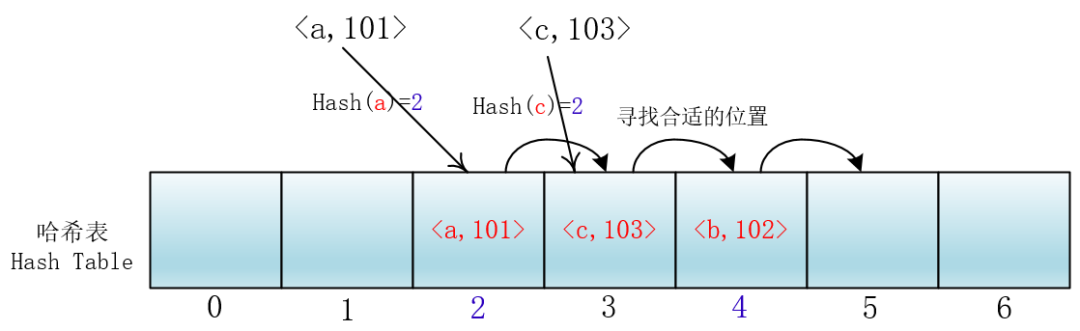
我们把这种方法称作线性探测法,我们可以将Hash以及寻找位置的过程抽象成一个函数:

所以关键字要进行查找或者插入,首先看(hash1(key)+0)%7 位置是自己最终的位置吗?如果有冲突,就探测(查看)下一个位置:(hash1(key)+1)%7。依次进行
所谓探测,就是在插入的时候检查哪个位置可以插入,或者查找时查找哪个位置是要查找的键值对,本质就是探寻这个键值对最终的位置。
但是这样会有一个问题,就是随着键值对的增多,会在哈希表里形成连续的键值对
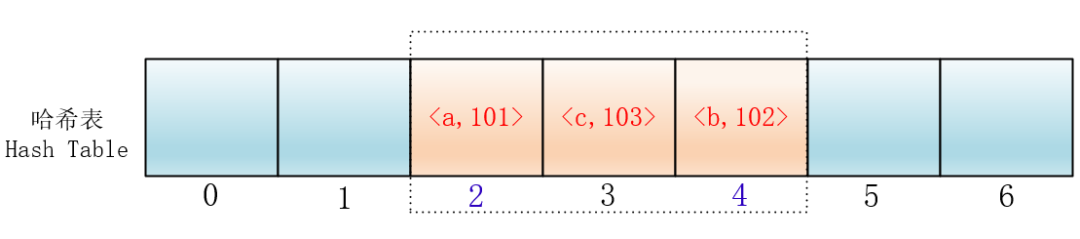
这样的话,当插入元素时,任意一个落入这个区间的元素都要一直探测到区间末尾,并且最终将自己加入到这个区间内。这样就会导致落在区间内的关键字Key要进行多次探测才能找到合适的位置,并且还会继续增大这个连续区间,使探测时间变得更长,这样的现象被称为“一次聚集(primary clustering)”


平方探测法

其实我们可以让它按照 i^2 的规律来跳跃探测
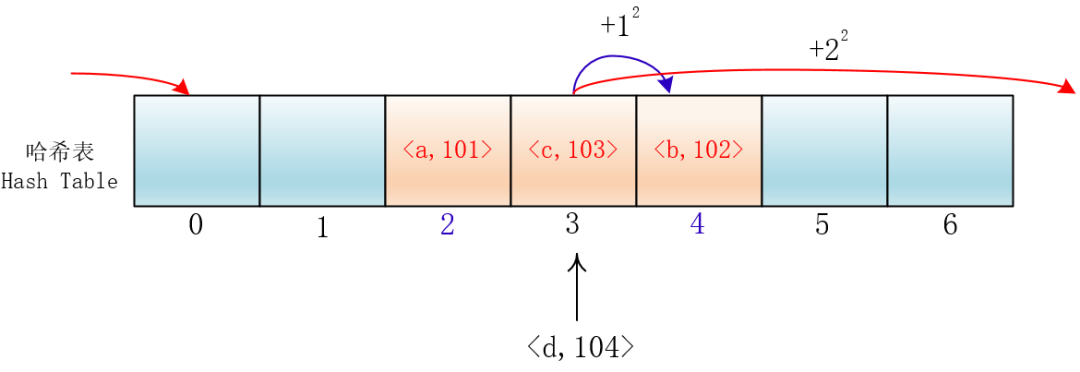
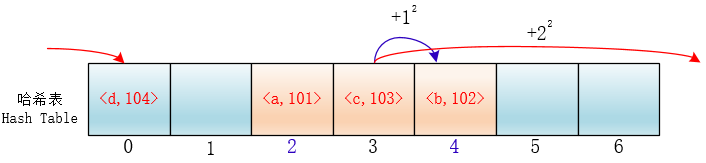
这样的话,元素就不会聚集在某一块区域了,我们把这种方法称为平方探测法
同样我们可以抽象成下面的函数:
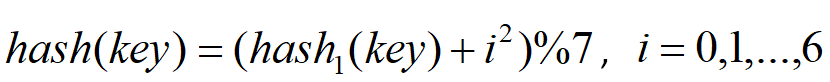
其实可以扩展到更一般的形式:
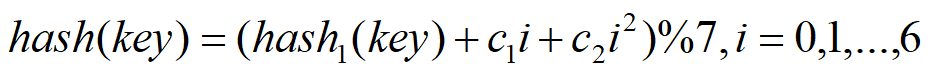
虽然平方探测法解决了线性探测法的一次聚集,但是它也有一个小问题,就是关键字key散列到同一位置后探测时的路径是一样的。
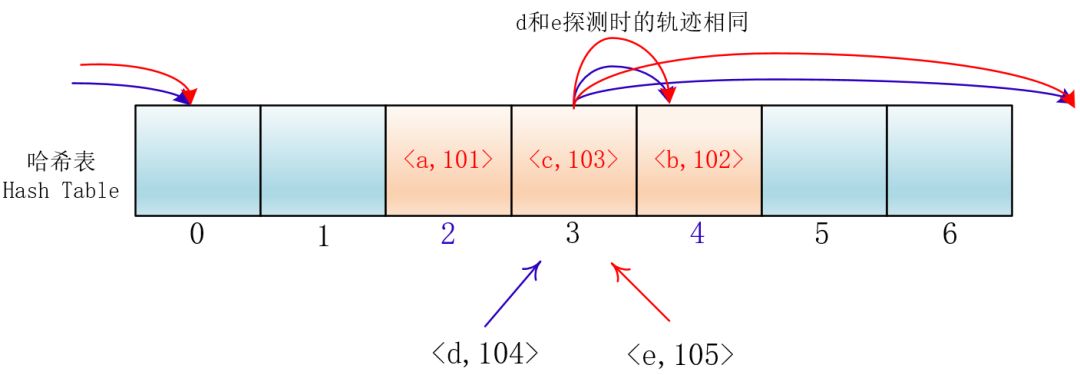
这样对于许多落在同一位置的关键字而言,越是后面插入的元素,探测的时间就越长。
这种现象被称作“二次聚集(secondary clustering)”,其实这个在线性探测法里也有。
这种现象出现的原因是由于对于落在同一个位置的关键字我们采取了一个依赖 i 的函数(i或者i^2)来进行探测,它不会因为关键字的不同或其他因素而改变探测的路径。那么我们是不是可以让探测的方法依赖于关键字呢?
双散列
答案是可以的,我们可以再弄另外一个Hash函数,对落在同一个位置的关键字进行再次的Hash,探测的时候就用依赖这个Hash值去探测,比如我们可以使用下面的函数:
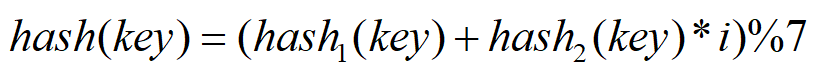
经过hash1的散列后,会定位到某一个地址,如果这个地址冲突,那么就按照1hash2(key)、2hash2(key)… 的偏移去探测合适的位置。
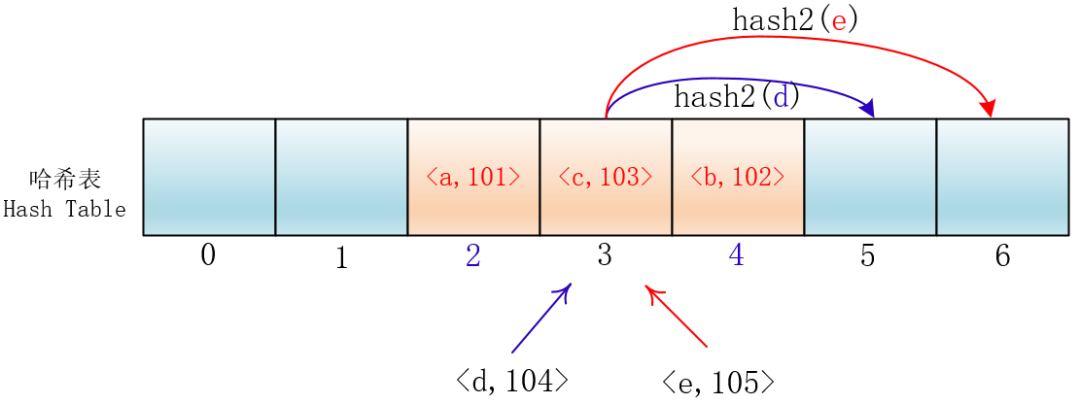
由于Hash2函数不同于Hash1,所以两个不同的关键字Hash1值和Hash2值同时相同的概率就会变得非常低。
这样就避免了二次聚集,但同时也付出了计算另一个散列函数Hash2的代价。



