HashMap树化连环炮
1. 为什么要进行树化?
我们看一下官方的描述
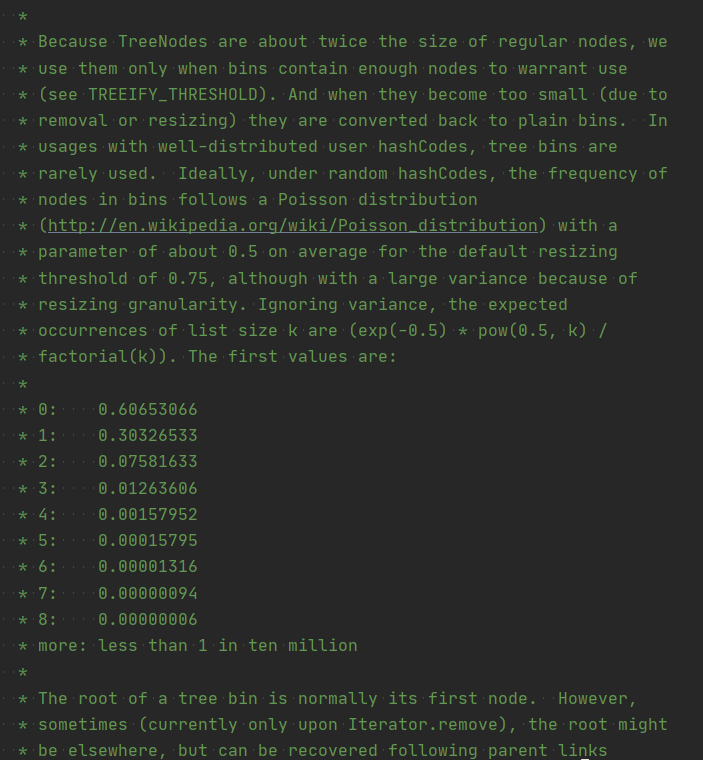
简单翻译一下:
由于TreeNodes的大小大约是常规节点的两倍,因此我们仅在容器包含足够的节点以保证使用时才使用它们(参见 TREEIFY_THRESHOLD 值)。当它们变得太小(由于移除或调整大小)时,它们会被转换回普通的bin。理想情况下,在随机哈希代码下,bin中的节点频率遵循泊松分布,下面就是list size k 的频率表。
- 0:0.60653066
- 1:0.30326533
- 2:0.07581633
- 3:0.01263606
- 4:0.00157952
- 5:0.00015795
- 6:0.00001316
- 7:0.00000094
- 8:0.00000006
其他:少于一百万分之十
2. 为什么链表长度为8的概率如此之低,还要去树化?
这里科普一个东西:Hash碰撞攻击,就是说,有人恶意的向服务器发送一些hash值计算出来一样,但是又不相同的数据,用我们的Java语言来理解就是:
a.hash()= =b.hash() , a.equals(b)= =false
这样,我们的HashMap会把这些数据全部加入到同一个位置,即一条链表上,倘若我们的链表长度达到了100,那么可想而知,性能急剧下降。这时我们的红黑树可以缓解这种性能急剧下降的问题,但是最好的解决方案是去拦截这些恶意的攻击。
3. 为什么不选择6进行树化?
我们看一下TreeNode的源码
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
........
}
这是node节点,继承了Map.Entry
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
对比发现:TreeNode每一个数都是一个TreeNode,正如官方所说的,TreeNode大概是普通的2倍,所以我们转换成树结构时会加大内存开销的。
我们发现在加载因子没有修改的前提下,单一条链表的长度大于等于8的概率是非常的低的,所以我们选择8才树化,树化的频率还是很低的,HashMap整体性能受到影响还是比较小的。
如果选择6进行树化,虽然概率也很低,但是也比8大了一千倍,遇到组合Hash攻击时(让你每个链表都进行树化),也会遇到性能下降的问题。
4. 为什么树化之后,当长度减至6的时候,还要进行反树化?
- 长度为6时我们查询次数是6,而红黑树是3次,但是消耗了一倍的内存空间,所以我们认为,转换回链表是有必要的。
- 维护一颗红黑树比维护一个链表要复杂,红黑树有一些左旋右旋等操作来维护顺序,而链表只有一个插入操作,不考虑顺序,所以链表的内存开销和耗时在数据少的情况下是更优的选择。
5. 为什么在JDK1.8中进行对HashMap优化的时候,把链表转化为红黑树的阈值是8,而不是7或者不是20呢?
如果选择6和8(如果链表小于等于6树还原转为链表,大于等于8转为树),中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
还有一点重要的就是由于treenodes的大小大约是常规节点的两倍,因此我们仅在容器包含足够的节点以保证使用时才使用它们,当它们变得太小(由于移除或调整大小)时,它们会被转换回普通的node节点,容器中节点分布在hash桶中的频率遵循泊松分布,桶的长度超过8的概率非常非常小。所以作者应该是根据概率统计而选择了8作为阀值
评论(2)
8数化 6链化 其实是在效率与内存之间找平衡
8数化 6链化