MySQL 索引(三)
- 什么是覆盖索引?
- 什么情况下会用到覆盖索引?
- 覆盖索引有什么好处?
- 什么是最左前缀原则?
- 什么情况下最左前缀原则会失效?
- 什么是索引下推?
- 索引下推有什么好处?
覆盖索引
在讲覆盖索引之前,我们还是先来看一个例子。其实这个例子,我们在上一篇文章中也提到过。
假如有这么一个数据表:
| user_id (主键) | name | age | city |
|---|---|---|---|
| 1 | Alice | 24 | New York |
| 2 | Bob | 30 | London |
| 3 | Charlie | 28 | Beijing |
主键索引树是这样的:
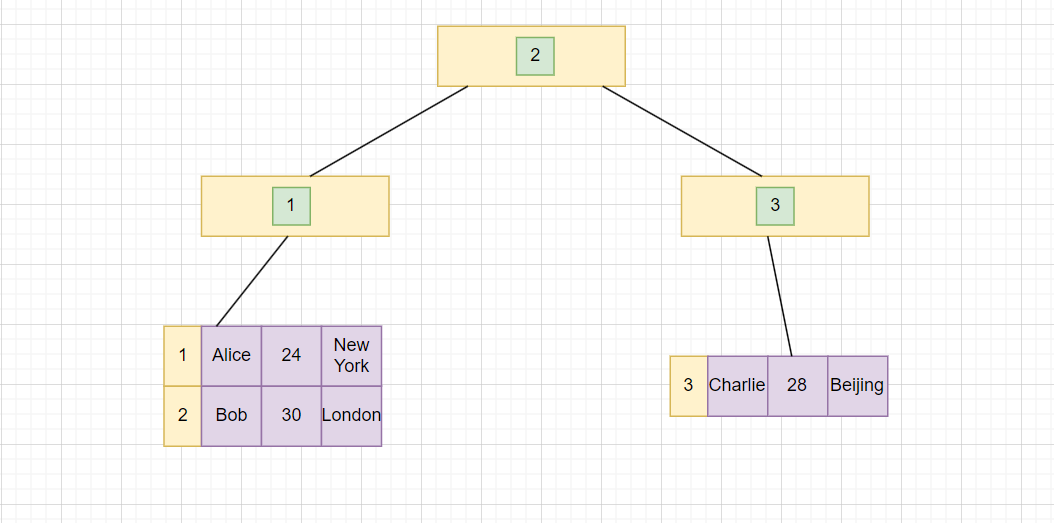
然后我们在 name 上再创建一个索引,也就是辅助索引:
CREATE INDEX idx_name ON users(name);
那么辅助索引树是这样的:
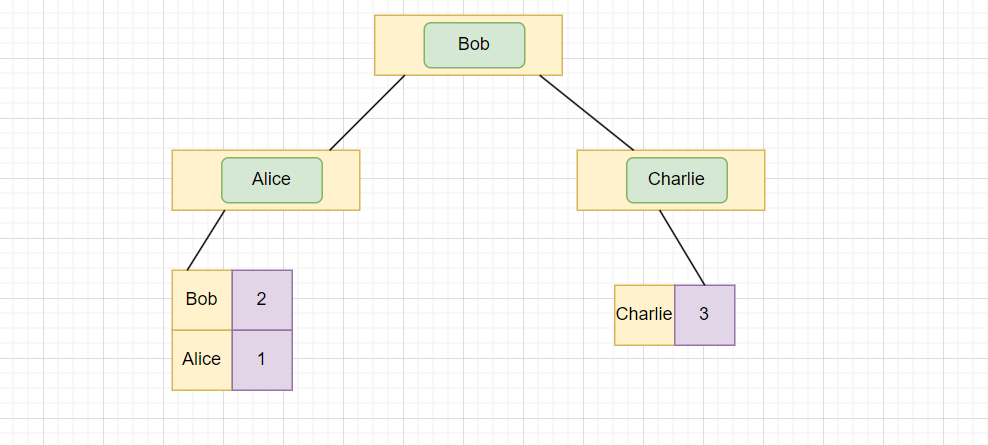
然后我们执行这个语句:
SELECT * FROM users WHERE name = 'Bob';
我们想查询关于 Bob 的所有信息,查询过程是先在辅助索引树中查询到 user_id ,然后再去主键索引树中根据 user_id 查询数据行,这个过程叫做回表。关于回表的概念,我们在上一篇文章也已经提到过了。
假如我们只查询 Bob 的 user_id :
SELECT user_id FROM users WHERE name = 'Bob';
查询过程就是只需要在辅助索引树中进行查询,然后返回结果就可以了,不需要再去主键索引树中进行第二次查询。
实际上,这个过程就叫做 **覆盖索引 **。
覆盖索引 是一种索引优化技术,它指的是查询中所需的所有列的数据都可以直接从索引中获取,而无需访问表中的实际行(也就是回表操作)。
覆盖索引的特点就是查询的 SELECT 字段全部包含在索引中,不需要从数据页中读取记录,直接从索引中获取数据,这样就减少了树的搜索次数,也就减少了磁盘 I/O 的次数。
换句话说,覆盖索引能够覆盖查询所需的数据,从而提高查询性能。
基于上面覆盖索引的说明,我们来讨论一个问题:在一个市民信息表上,是否有必要将身份证号和名字建立联合索引?
我们现在假设一个数据表的结构是这样的:
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`id_card` varchar(32) DEFAULT NULL, -- 身份证号,已经有单列索引
`name` varchar(32) DEFAULT NULL, -- 姓名,与 `age` 组成了联合索引
`age` int(11) DEFAULT NULL,
`ismale` tinyint(1) DEFAULT NULL,
PRIMARY KEY (`id`), -- 聚簇索引
KEY `id_card` (`id_card`), -- 单列索引
KEY `name_age` (`name`, `age`) -- 联合索引
) ENGINE=InnoDB;
从这个表中,我们可以看到,目前已经存在的索引有:
- 主键索引 id:用于唯一标识每行记录。
- 单列索引 id_card:支持基于身份证号的高效查询。
- 联合索引 name_age:支持基于 name 和 age 的联合查询。
如果我们只根据身份证号去查询市民的某些信息,那么只创建一个单列索引 id_card 就已经足够了,是不需要联合索引的。
但是,如果现在有一个高频请求,要根据市民的身份证号查询他的姓名呢?
比如这条语句:
SELECT name FROM tuser WHERE id_card = '123456789012345678';
我们来分析一下它的查询过程:因为表中存在 id_card 单列索引,所以 MySQL 会利用 id_card 索引快速定位到满足条件的记录。但是,由于 name 不在 id_card 索引中,所以 MySQL 需要通过回表(访问主键索引 id 所在的主键索引树)获取完整的行数据,再取出 name 列。
这样做的结果就是,每次查询都需要通过 id_card 索引找到对应的主键值,然后访问主键所在的主键索引树来获取 name 列。回表操作会增加额外的磁盘 I/O,尤其在高频请求场景下会导致性能下降。
为了优化这个查询,我们就可以考虑使用覆盖索引了。
下面,我们为 id_card 和 name 创建联合索引。
ALTER TABLE tuser ADD KEY `id_card_name` (`id_card`, `name`);
当联合索引创建完成之后,再执行上面的查询语句,查询过程就是这样的:MySQL 会直接从 id_card_name 索引中找到满足条件的 id_card,并读取对应的 name 值。因为 name 已经包含在索引中,减少了对聚簇索引的访问,也就是不需要回表了,查询效率显著提升了。
当然,如果 id_card 和 name 的联合查询较少,已有的单列索引 id_card 和联合索引 name_age 可以满足大部分需求,那么就不需要创建新的索引,避免冗余,因为维护索引也是需要成本的。
在这个章节中,我们了解了什么是覆盖索引,并且结合具体的场景讲解了覆盖索引的优点,以及在什么情况下可以使用联合索引。
最左前缀原则
下面我们再来了解一个在数据库中比较重要的原则,叫做最左前缀原则。
最左前缀原则是指,当使用联合索引时,MySQL 会根据索引的最左边列开始进行匹配,并依次向右匹配,直到遇到范围查询或某列缺失时停止匹配。
换句话说,联合索引的匹配是按照索引从左到右的顺序逐列进行的,一旦跳过一列或遇到范围查询,就无法再利用后面的列了。
我们还是结合具体例子来看。
假设有一个用户表 users :
CREATE TABLE users (
id INT NOT NULL,
name VARCHAR(50),
age INT,
city VARCHAR(50),
PRIMARY KEY (id),
INDEX idx_name_age_city (name, age, city) -- 创建了一个联合索引
);
在表中有一个联合索引:idx_name_age_city,它包含三列:name、age、city,按顺序从左到右排列。
接下来会有五条 SQL 语句,我们分别来进行分析,看看它们在利用联合索引时有什么不同。
第一个 SQL :
SELECT * FROM users WHERE name = 'Alice';
是可以使用联合索引的。因为 name 是联合索引的第 1 列,也就是最左边的列,所以完全符合最左前缀原则。
第二个 SQL :
SELECT * FROM users WHERE name = 'Alice' AND age = 25;
是可以使用索引的。因为我们按顺序使用了联合索引的第 1 列(name)和第 2 列(age)。
第三个 SQL:
SELECT * FROM users WHERE name = 'Alice' AND age > 25 AND city = 'Beijing';
可以使用部分索引,但不是全部。MySQL 可以利用索引的前两列 name 和 age。但是由于 age > 25 是范围查询,所以匹配会在这里终止,无法再继续使用索引中的 city 列。因为在讲定义的时候,我们已经提到过了,范围查询会中断后续索引列的匹配。
第四个 SQL :
SELECT * FROM users WHERE age = 25 AND city = 'Beijing';
不能使用索引。因为我们跳过了索引的第 1 列 name ,直接从第 2 列 age 开始查询。因为定义中我们提到过,最左前缀原则要求必须从最左边列开始匹配,不能跳过任何一列。
第五个 SQL :
SELECT * FROM users WHERE name LIKE 'A%' AND age = 25;
可以使用索引。因为 name LIKE ‘A%’ 仍然是对索引第一列的前缀匹配,符合最左前缀原则。
现在我们对以上五种情况来做一个总结,加深一下印象:
假设现在有一个联合索引(x,y,z)。
当查询条件是这样的时候,联合索引都是可以匹配上的:
- where x = 1 and y = 2 and z = 3
- where x = 1 and y = 2
- where x = 1
但是当查询条件是这样时,联合索引就没有办法匹配了:
- where y = 2 and z = 3
- where z = 3
- where y = 2
我们再来强调一下“最左前缀”这个概念,之所以叫“最左前缀”,是因为 MySQL 索引匹配时,只能从索引定义的最左列开始,且按顺序匹配,像一个从左到右的搜索规则。如果最左边的列都不符合条件或被跳过,那么这个索引也就不生效了。
所以,结合我们学习的这几种情况,当使用联合索引的时候,我们尽量按照联合索引的顺序来使用查询条件,比如
如果索引是 (name, age, city),查询条件最好是从 name 开始;另外,也要避免在中间使用范围查询,因为后面列的索引会失效。
好,在这一章节,我们学习了一个非常重要的原则——最左前缀原则。我们分析了在什么情况下联合索引是有效的,以及在什么情况下联合索引会失效。而且,我们还强调了在使用联合索引时要注意的一些问题。
索引下推
我们还是延续上一章节的表结构继续讲。
CREATE TABLE users (
id INT NOT NULL,
name VARCHAR(50),
age INT,
city VARCHAR(50),
PRIMARY KEY (id),
INDEX idx_name_age_city (name, age, city) -- 创建了一个联合索引
);
假设表中有以下数据:
| id | name | age | city |
|---|---|---|---|
| 1 | Alice | 30 | Beijing |
| 2 | Bob | 40 | Shanghai |
| 3 | Alice | 35 | Shanghai |
| 4 | Alice | 25 | Beijing |
| 5 | Charlie | 50 | Beijing |
我们来执行这个查询语句:
SELECT id, name, age, city
FROM users
WHERE name = 'Alice' AND age > 30 AND city = 'Shanghai';
在这个查询语句中,有三个查询条件:
- name = ‘Alice’ 是索引中的第一列。
- age > 30 是索引中的第二列。
- city = ‘Shanghai’ 是索引中的第三列。
在上一章我们提到,遇到范围查询时,后面的列就不会走索引了。
那么,它具体是怎么执行的呢?我们来分析一下。
在MySQL 5.6 之前,MySQL 存储引擎会先使用索引筛选第一列 name = ‘Alice’ ,找到 name = ‘Alice’ 的所有记录:
(Alice, 30, Beijing)
(Alice, 35, Shanghai)
(Alice, 25, Beijing)
然后对于每一条索引记录,存储引擎会回到表中,取出完整数据,也就是说 ,MySQL 会对每条数据一一回表。回表后的数据集是:
(1, Alice, 30, Beijing)
(3, Alice, 35, Shanghai)
(4, Alice, 25, Beijing)
最后,在服务器层过滤 age > 30 和 city = ‘Shanghai’ 。拿到最终符合条件的记录:
(3, Alice, 35, Shanghai)
我们会发现一个问题,那就是即使索引中已经有 age 和 city 的信息,MySQL 在开始的时候仍然没有利用它,而是对第一次筛选出的数据进行一一回表之后再取出完整数据后再过滤,这样的话性能就很差。
但是从MySQL 5.6 及之后就解决了这个问题。
第一步,同样的,MySQL 存储引擎会先使用索引筛选第一列 name = ‘Alice’ ,找到 name = ‘Alice’ 的所有记录:
(Alice, 30, Beijing)
(Alice, 35, Shanghai)
(Alice, 25, Beijing)
存储引擎利用索引的其他列 age 和 city 直接过滤数据,而不是像 MySQL5.6 之前那样对每条数据进行一一回表。经过索引过滤后,剩下的索引记录是:
(Alice, 35, Shanghai)
最后只对剩下的记录回表,取出完整数据:
(3, Alice, 35, Shanghai)
实际上,这个过程就叫做 索引下推 **。在这个查询中,MySQL 会利用 idx_name_age_city 这个联合索引来优化查询过程。而 索引下推 会让存储引擎尽可能多地利用索引条件过滤掉不符合的数据,从而减少回表次数。 **
索引下推让存储引擎层直接过滤掉了大部分无关记录,减少了回表次数,提高了查询效率。
我们用一个生活化的例子类比。假如你是一家快递公司的员工,需要从仓库中找到所有寄往 北京 且重 大于 10kg 的包裹。
没有使用索引下推时:
- 你会先从仓库里拿出所有重 大于 10kg 的包裹(不管目的地是哪里),然后逐一打开,查看是否寄往北京。
- 如果有 1000 个包裹重大于 10kg,但只有 100 个是寄往北京的,那你就浪费了很多时间搬运。
使用索引下推时:
- 在仓库里,你直接检查每个包裹的重量和目的地,只挑出 重大于 10kg 且寄往北京 的包裹带走。
- 如果一开始就过滤掉了不符合条件的包裹,你的工作量会大大减少。
在这一章,我们结合一个查询语句介绍了索引下推的概念,以及索引下推的具体过程。
总结
这篇文章,我们一共讲解了三个部分的知识,分别是覆盖索引、最左前缀原则、索引下推。如果你认真阅读了,你就会发现,这三个知识点其实有一个共同的优点,那就是都减少了数据的查询次数。所以,以后在我们设计数据库的时候,我们也要尽量遵循这个原则,也就是通过减少数据的查询次数来提高查询效率,从而减少资源消耗。