拼写纠错是如何实现的?
(1)拼写纠错是基于编辑距离来实现;编辑距离是一种标准的方法,它用来表示经过插入、删除和替换操作从一个字符串转换到另外一个字符串的最小操作步数;
(2)编辑距离的计算过程:比如要计算 batyu 和 beauty 的编辑距离,先创建一个7×8 的表(batyu 长度为 5,coffee 长度为 6,各加 2),接着,在如下位置填入黑色数字。其他格的计算过程是取以下三个值的最小值:
如果最上方的字符等于最左方的字符,则为左上方的数字。否则为左上方的数字+1。(对于 3,3 来说为 0)
左方数字+1(对于 3,3 格来说为 2)
上方数字+1(对于 3,3 格来说为 2)
最终取右下角的值即为编辑距离的值 3。
对于拼写纠错,我们考虑构造一个度量空间(Metric Space),该空间内任何关系满足以下三条基本条件:
d(x,y) = 0 — 假如 x 与 y 的距离为 0,则 x=y
d(x,y) = d(y,x) — x 到 y 的距离等同于 y 到 x 的距离
d(x,y) + d(y,z) >= d(x,z) — 三角不等式
(1)根据三角不等式,则满足与 query 距离在 n 范围内的另一个字符转 B,其与 A的距离最大为 d+n,最小为 d-n。
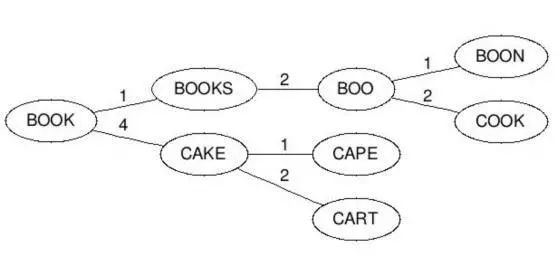
(2)BK 树的构造就过程如下:每个节点有任意个子节点,每条边有个值表示编辑距离。所有子节点到父节点的边上标注 n 表示编辑距离恰好为 n。比如,我们有棵树父节点是”book”和两个子节点”cake”和”books”,”book”到”books”的边标号 1,”book”到”cake”的边上标号 4。从字典里构造好树后,无论何时你想插入新单词时,计算该单词与根节点的编辑距离,并且查找数值为d(neweord, root)的边。递归得与各子节点进行比较,直到没有子节点,你就可以创建新的子节点并将新单词保存在那。比如,插入”boo”到刚才上述例子的树中,我们先检查根节点,查找 d(“book”, “boo”) = 1 的边,然后检查标号为1 的边的子节点,得到单词”books”。我们再计算距离 d(“books”, “boo”)=2,则将新单词插在”books”之后,边标号为 2。
3、查询相似词如下:计算单词与根节点的编辑距离 d,然后递归查找每个子节点标号为 d-n 到 d+n(包含)的边。假如被检查的节点与搜索单词的距离 d 小于 n,则返回该节点并继续查询。比如输入 cape 且最大容忍距离为 1,则先计算和根的编辑距离 d(“book”, “cape”)=4,然后接着找和根节点之间编辑距离为 3 到5 的,这个就找到了 cake 这个节点,计算 d(“cake”, “cape”)=1,满足条件所以返回 cake,然后再找和 cake 节点编辑距离是 0 到 2 的,分别找到 cape 和cart 节点,这样就得到 cape 这个满足条件的结果。