Spring如何解决循环依赖问题(超详细)
- FileSystemXmlApplicationContext:此容器从一个 XML 文件中加载beans 的定义,XML Bean 配置文件的全路径名必须提供给它的构造函数。
-
ClassPathXmlApplicationContext:此容器也从一个 XML 文件中加载beans 的定义,这里,你需要正确设置 classpath 因为这个容器将在 classpath 里找 bean 配置。
-
WebXmlApplicationContext:此容器加载一个 XML 文件,此文件定义了一个 Web 应用的所有 bean。
Spring如何解决循环依赖问题
了解问题的本质再分析问题,往往更利于对问题有更深入的了解和研究。所以我们在分析 Spring 关于循环依赖的源码之前,先要了解下什么是循环依赖。
1. 循环依赖的概念
、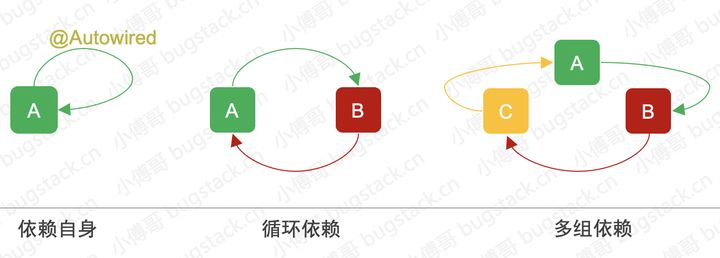
- 循环依赖分为三种,自身依赖于自身、互相循环依赖、多组循环依赖。
- 但无论循环依赖的数量有多少,循环依赖的本质是一样的。就是你的完整创建依赖于我,而我的完整创建也依赖于你,但我们互相没法解耦,最终导致依赖创建失败。
- 所以 Spring 提供了除了构造函数注入和原型注入外的,setter循环依赖注入解决方案。那么我们也可以先来尝试下这样的依赖,如果是我们自己处理的话该怎么解决。
2. 问题体现
public class ABTest {
public static void main(String[] args) {
new ClazzA();
}
}
class ClazzA {
private ClazzB b = new ClazzB();
}
class ClazzB {
private ClazzA a = new ClazzA();
}
- 这段代码就是循环依赖最初的模样,你中有我,我中有你,运行就报错
java.lang.StackOverflowError - 这样的循环依赖代码是没法解决的,当你看到 Spring 中提供了 get/set 或者注解,这样之所以能解决,首先是进行了一定的解耦。让类的创建和属性的填充分离,先创建出半成品Bean,再处理属性的填充,完成成品Bean的提供。
3. 问题处理
在这部分的代码中就一个核心目的,我们来自己解决一下循环依赖,方案如下:
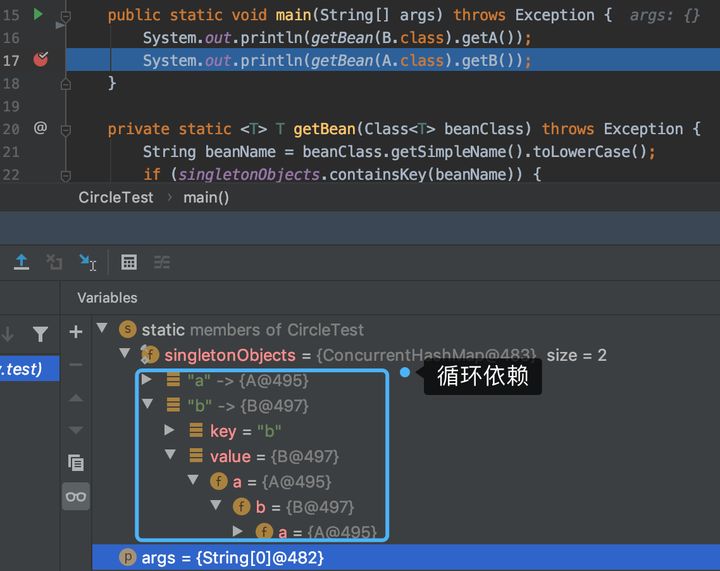
public class CircleTest {
private final static Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
public static void main(String[] args) throws Exception {
System.out.println(getBean(B.class).getA());
System.out.println(getBean(A.class).getB());
}
private static <T> T getBean(Class<T> beanClass) throws Exception {
String beanName = beanClass.getSimpleName().toLowerCase();
if (singletonObjects.containsKey(beanName)) {
return (T) singletonObjects.get(beanName);
}
// 实例化对象入缓存
Object obj = beanClass.newInstance();
singletonObjects.put(beanName, obj);
// 属性填充补全对象
Field[] fields = obj.getClass().getDeclaredFields();
for (Field field : fields) {
field.setAccessible(true);
Class<?> fieldClass = field.getType();
String fieldBeanName = fieldClass.getSimpleName().toLowerCase();
field.set(obj, singletonObjects.containsKey(fieldBeanName) ? singletonObjects.get(fieldBeanName) : getBean(fieldClass));
field.setAccessible(false);
}
return (T) obj;
}
}
class A {
private B b;
// ...get/set
}
class B {
private A a;
// ...get/set
}
这段代码提供了 A、B 两个类,互相有依赖。但在两个类中的依赖关系使用的是 setter 的方式进行填充。也就是只有这样才能避免两个类在创建之初不非得强依赖于另外一个对象。
getBean,是整个解决循环依赖的核心内容,A 创建后填充属性时依赖 B,那么就去创建 B,在创建 B 开始填充时发现依赖于 A,但此时 A 这个半成品对象已经存放在缓存到singletonObjects 中了,所以 B 可以正常创建,在通过递归把 A 也创建完整了。
四、源码分析
1. 说说细节
通过上面的例子我们大概了解到,A和B互相依赖时,A创建完后填充属性B,继续创建B,再填充属性A时就可以从缓存中获取了,如下:
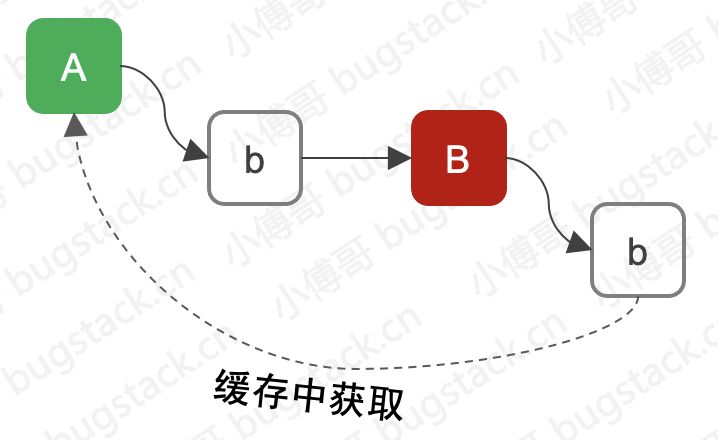
那这个解决事循环依赖的事放到 Spring 中是什么样呢?展开细节!

虽然,解决循环依赖的核心原理一样,但要放到支撑起整个 Spring 中 IOC、AOP 特性时,就会变得复杂一些,整个处理 Spring 循环依赖的过程如下;
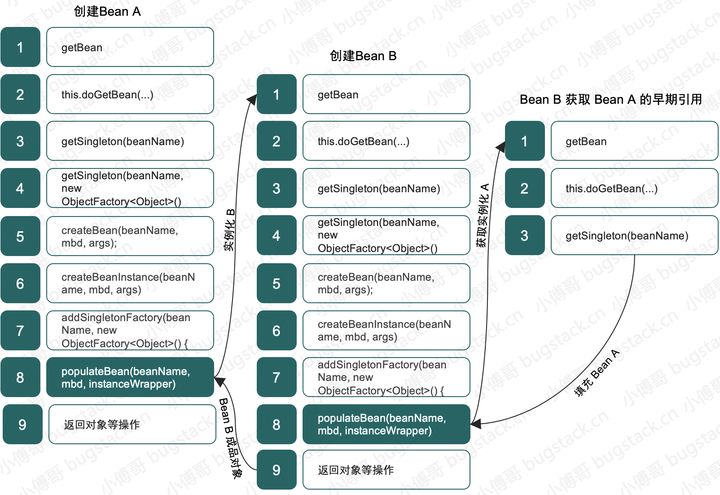
- 以上就是关于 Spring 中对于一个有循环依赖的对象获取过程,也就是你想要的
说说细节 - 乍一看是挺多流程,但是这些也基本是你在调试代码时候必须经过的代码片段,拿到这份执行流程,再调试就非常方便了。
2. 处理过程
关于本章节涉及到的案例源码分析,已更新到 github:https://github.com/fuzhengwei/interview – interview-31
以下是单元测试中对AB依赖的获取Bean操作,重点在于进入 getBean 的源码跟进;
@Test
public void test_alias() {
BeanFactory beanFactory = new ClassPathXmlApplicationContext("spring-config.xml");
Bean_A bean_a = beanFactory.getBean("bean_a", Bean_A.class);
logger.info("获取 Bean 通过别名:{}", bean_a.getBean_b());
}
org.springframework.beans.factory.support.AbstractBeanFactory.java
@Override
public <T> T getBean(String name, Class<T> requiredType) throws BeansException {
return doGetBean(name, requiredType, null, false);
}
- 从 getBean 进入后,获取 bean 的操作会进入到 doGetBean。
- 之所以这样包装一层,是因为 doGetBean 有很多不同入参的重载方法,方便外部操作。
doGetBean 方法
protected <T> T doGetBean(
final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)
throws BeansException {
// 从缓存中获取 bean 实例
Object sharedInstance = getSingleton(beanName);
// mbd.isSingleton() 用于判断 bean 是否是单例模式
if (mbd.isSingleton()) {
// 获取 bean 实例
sharedInstance = getSingleton(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
try {
// 创建 bean 实例,createBean 返回的 bean 实例化好的
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
}
});
// 后续的处理操作
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// ...
// 返回 bean 实例
return (T) bean;
}
- 按照在源码分析的流程图中可以看到,这一部分是从 getSingleton 先判断是否有实例对象,对于第一次进入是肯定没有对象的,要继续往下走。
- 在判断 mbd.isSingleton() 单例以后,开始使用基于 ObjectFactory 包装的方式创建 createBean,进入后核心逻辑是开始执行 doCreateBean 操作。
doCreateBean 方法
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args)
throws BeanCreationException {
// 创建 bean 实例,并将 bean 实例包装到 BeanWrapper 对象中返回
instanceWrapper = createBeanInstance(beanName, mbd, args);
// 添加 bean 工厂对象到 singletonFactories 缓存中
addSingletonFactory(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
// 获取原始对象的早期引用,在 getEarlyBeanReference 方法中,会执行 AOP 相关逻辑。若 bean 未被 AOP 拦截,getEarlyBeanReference 原样返回 bean。
return getEarlyBeanReference(beanName, mbd, bean);
}
});
try {
// 填充属性,解析依赖关系
populateBean(beanName, mbd, instanceWrapper);
if (exposedObject != null) {
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
}
// 返回 bean 实例
return exposedObject;
}
- 在 doCreateBean 方法中包括的内容较多,但核心主要是创建实例、加入缓存以及最终进行属性填充,属性填充就是把一个 bean 的各个属性字段涉及到的类填充进去。
createBeanInstance,创建 bean 实例,并将 bean 实例包装到 BeanWrapper 对象中返回addSingletonFactory,添加 bean 工厂对象到 singletonFactories 缓存中getEarlyBeanReference,获取原始对象的早期引用,在 getEarlyBeanReference 方法中,会执行 AOP 相关逻辑。若 bean 未被 AOP 拦截,getEarlyBeanReference 原样返回 bean。populateBean,填充属性,解析依赖关系。也就是从这开始去找寻 A 实例中属性 B,紧接着去创建 B 实例,最后在返回回来。
getSingleton 三级缓存
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从 singletonObjects 获取实例,singletonObjects 是成品 bean
Object singletonObject = this.singletonObjects.get(beanName);
// 判断 beanName ,isSingletonCurrentlyInCreation 对应的 bean 是否正在创建中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// 从 earlySingletonObjects 中获取提前曝光未成品的 bean
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 获取相应的 bean 工厂
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 提前曝光 bean 实例,主要用于解决AOP循环依赖
singletonObject = singletonFactory.getObject();
// 将 singletonObject 放入缓存中,并将 singletonFactory 从缓存中移除
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
singletonObjects.get(beanName),从 singletonObjects 获取实例,singletonObjects 是成品 beanisSingletonCurrentlyInCreation,判断 beanName ,isSingletonCurrentlyInCreation 对应的 bean 是否正在创建中allowEarlyReference,从 earlySingletonObjects 中获取提前曝光未成品的 beansingletonFactory.getObject(),提前曝光 bean 实例,主要用于解决AOP循环依赖
综上,是一个处理循环依赖的代码流程,这部分提取出来的内容主要为核心内容,并没与长篇大论的全部拆取出来,大家在调试的时候会涉及的比较多,尽可能要自己根据流程图操作调试几遍。
3. 依赖解析
综上从我们自己去尝试解决循环依赖,学习了循环依赖的核心解决原理。又分析了 Spring 解决的循环依赖的处理过程以及核心源码的分析。那么接下来我们在总结下三级缓存分别不同的处理过程,算是一个总结,也方便大家理解。
1. 一级缓存能解决吗?
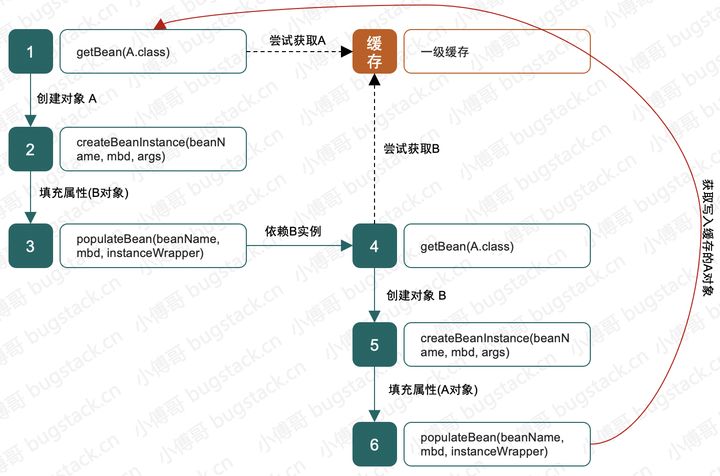
- 其实只有一级缓存并不是不能解决循环依赖,就像我们自己做的例子一样。
- 但是在 Spring 中如果像我们例子里那么处理,就会变得非常麻烦,而且也可能会出现 NPE 问题。
- 所以如图按照 Spring 中代码处理的流程,我们去分析一级缓存这样存放成品 Bean 的流程中,是不能解决循环依赖的问题的。因为 A 的成品创建依赖于 B,B的成品创建又依赖于 A,当需要补全B的属性时 A 还是没有创建完,所以会出现死循环。
2. 二级缓存能解决吗?
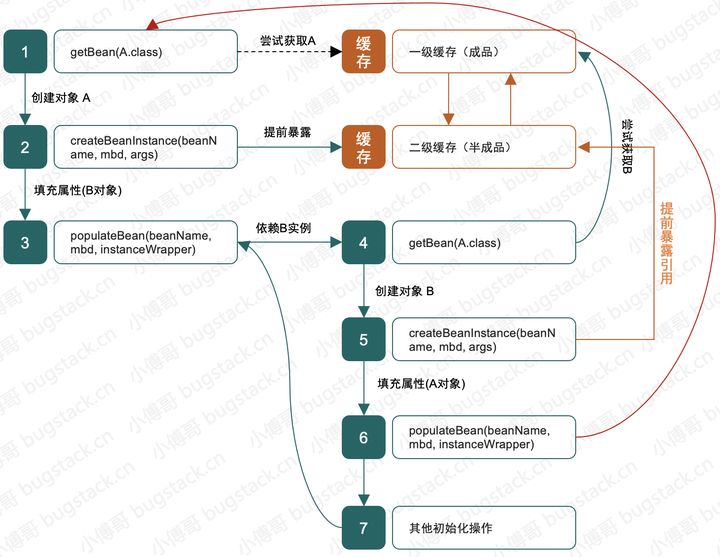
- 有了二级缓存其实这个事处理起来就容易了,一个缓存用于存放成品对象,另外一个缓存用于存放半成品对象。
- A 在创建半成品对象后存放到缓存中,接下来补充 A 对象中依赖 B 的属性。
- B 继续创建,创建的半成品同样放到缓存中,在补充对象的 A 属性时,可以从半成品缓存中获取,现在 B 就是一个完整对象了,而接下来像是递归操作一样 A 也是一个完整对象了。
3. 三级缓存解决什么?
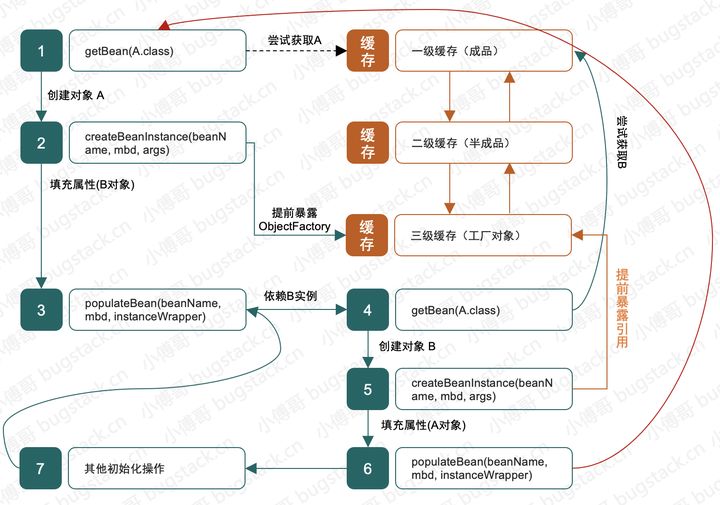
有了二级缓存都能解决 Spring 依赖了,怎么要有三级缓存呢。其实我们在前面分析源码时也提到过,三级缓存主要是解决 Spring AOP 的特性。AOP 本身就是对方法的增强,是 ObjectFactory<?> 类型的 lambda 表达式,而 Spring 的原则又不希望将此类类型的 Bean 前置创建,所以要存放到三级缓存中处理。
其实整体处理过程类似,唯独是 B 在填充属性 A 时,先查询成品缓存、再查半成品缓存,最后在看看有没有单例工程类在三级缓存中。最终获取到以后调用 getObject 方法返回代理引用或者原始引用。
至此也就解决了 Spring AOP 所带来的三级缓存问题。本章节涉及到的 AOP 依赖有源码例子,可以进行调试
五、总结
- 回顾本文基本以实际操作的例子开始,引导大家对循环依赖有一个整体的认识,也对它的解决方案可以上手的例子,这样对后续的关于 Spring 对循环依赖的解决也就不会那么陌生了。
- 通篇全文下来大家也可以看到,三级缓存并不是非必须不可,只不过在满足 Spring 自身创建的原则下,是必须的。如果你可以下载 Spring 源码对这部分代码进行改动下,提前创建 AOP 对象保存到缓存中,那么二级缓存一样可以解决循环依赖问题。
- 关于循环依赖可能并不是一个好的编码方式,如果在自己的程序中还是要尽可能使用更合理的设计模式规避循环依赖,可能这些方式会增加代码量,但在维护上会更加方便。当然这不是强制,可以根据你的需要而来。
评论(2)
帅地,我想问一下,这里解决循环依赖的方法,是不是只对单例Bean的创建有用?
清晰